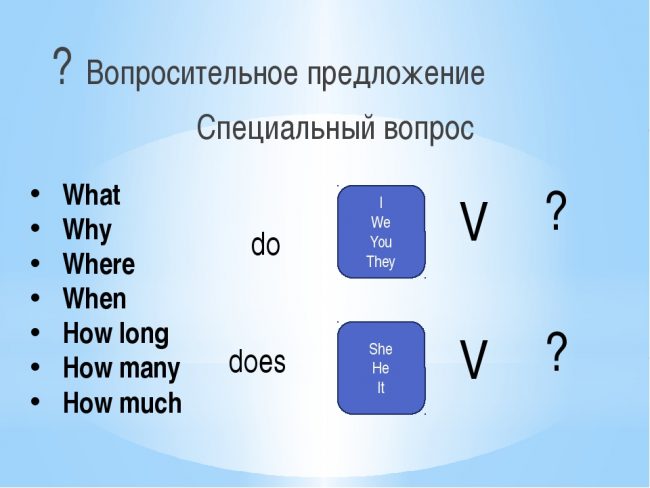
When does cluster feeding stop
What Is Cluster Feeding? 6 Tips for Cluster-Feeding Newborns
Cluster feeding is a developmental phase when babies’ feedings are spaced closely together. A cluster-feeding newborn may want lots of shorter feedings over a few hours at certain times during the day and may go for longer periods between feedings at other times. Cluster feeding is completely normal, and it often occurs during the initial days and months of breastfeeding.
Cluster feeding more commonly occurs in the later part of the afternoon or during the early evening hours. But it can happen at any time during the day. Babies may sleep longer after a session of cluster feeding.
Take a quiz
Find out what you can do with our Health Assistant
Some of the possible causes of cluster feeding are:
- A growth spurt. When going through a growth spurt, babies’ bodies need more nourishment. Because they need more nutrients and calories than normal, they need to eat more frequently.
- A developmental milestone. Babies move through many developmental milestones during the first six months after they’re born. When these physical and psychological changes are taking place, babies may need more nutrition. This may entice them to cluster feed, which may also soothe and calm them.
Cluster feeding can occur at any time during the life of a newborn. The first episode may occur shortly after birth. Newborn cluster feeding helps stimulate mothers’ breasts to secrete more milk. As babies develop, growth spurts may cause them to cluster feed to consume more nutrients. Cluster feeding generally ends when babies are around six months old.
Cluster feeding usually happens in phases. Babies may feed more frequently than usual for a few hours during the day, usually during the evening.
Cluster-feeding benefits and challenges
Here are some benefits and issues associated with cluster feeding.
Benefits of cluster feeding
Cluster feeding helps provide the nourishment that babies need during a growth spurt. It also helps soothe and calm a fussy baby. When cluster feeding, the baby is cozy in the arms of their parent. This provides security and comfort and satisfies their emotional requirements.
It also helps soothe and calm a fussy baby. When cluster feeding, the baby is cozy in the arms of their parent. This provides security and comfort and satisfies their emotional requirements.
Cluster feeding also promotes better sleep, and babies may sleep longer after filling up their stomachs with milk.
Cluster feeding may also boost milk supply. When babies eat more frequently, the breasts may produce more milk in response. In fact, some people encourage cluster feeding to increase their milk production.
Cluster-feeding challenges
Cluster feeding may be draining emotionally and physically. Many parents who cluster feed their babies feel frustrated and exhausted. Some people may think they’ve failed if they aren’t able to breastfeed. Others may be concerned about not having enough milk if their baby takes a long time to settle down. It may also feel like the breasts are empty. There’s always milk in the breasts, though, and they don’t become completely empty.
During newborn cluster-feeding sessions:
- Babies may have shorter periods of sleep or rest between feedings.
- Babies may eat for a couple of minutes and then pull on and off the breast.
- Babies may cry and become fussy.
Here are some tips for healthy cluster feeding:
1. Find a breastfeeding partner
A breastfeeding partner is someone who can bring drinks and snacks and provide entertainment during the cluster-feeding episodes.
2. Drink enough
Breastfeeding is a thirsty job. Feeling parched and thirsty is normal, especially during episodes of newborn cluster feeding. With a newborn constantly nursing, it’s important to drink lots of fluids to stay hydrated. Drink plenty of water. It’s helpful to have a glass of water nearby when starting to feed the baby. Make sure to drink water every couple of hours throughout the day.
3. Be prepared
Babies generally develop a routine around cluster feeding.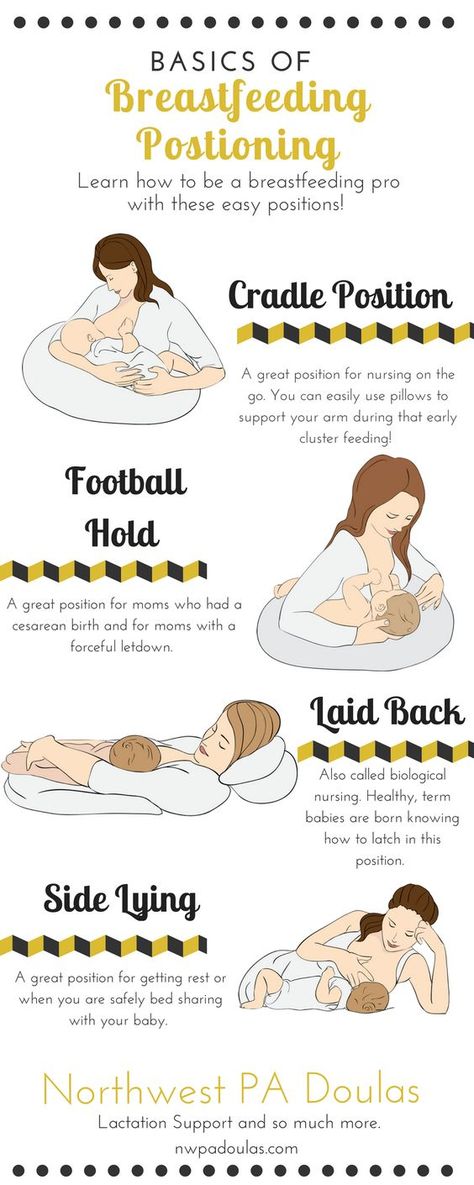 Babies may eat every evening between 6:00 p.m. and 10:00 p.m. When the baby’s typical schedule becomes clearer, it can be easier to make plans for the day accordingly. However, some babies start cluster feeding abruptly. Try to be flexible, and listen to the baby’s demands.
Babies may eat every evening between 6:00 p.m. and 10:00 p.m. When the baby’s typical schedule becomes clearer, it can be easier to make plans for the day accordingly. However, some babies start cluster feeding abruptly. Try to be flexible, and listen to the baby’s demands.
4. Eat well
To produce enough milk to fulfill the baby’s needs, the body requires lots of fuel. Eating small meals throughout the day can help. Some examples of nutritional snacks are whole-wheat crackers and hummus, peanut butter and apple slices, and almonds. These can help keep the body’s energy up during newborn cluster-feeding episodes. Don’t skip meals!
5. Get comfortable
When babies are going through a cluster-feeding episode, it’s easy to get stuck in one place. If possible, planning ahead of time can help make the cluster-feeding times more comfortable. Keep some magazines, books, smartphone, tablet, or TV remote nearby for entertainment during this time.
6. Know when the baby’s hungry
Pay attention to the baby’s hunger cues and offer them the chance to eat immediately. Crying is a late signal of hunger, so try to look for earlier hunger cues in a cluster-feeding newborn.
Crying is a late signal of hunger, so try to look for earlier hunger cues in a cluster-feeding newborn.
Cluster feeding is when a baby wants lots of shorter feedings over a few hours. It is more common when babies start breastfeeding and usually occurs during the early hours of the evening. It commonly happens when babies are going through a growth spurt or developmental milestone. It usually ends when a child turns six months old.
To cluster feed healthily, eat well and stay hydrated, make breastfeeding comfortable, and learn the baby’s hunger cues.
What Is Cluster Feeding & How Long Will It Last
Cluster feeding is a normal newborn feeding behavior, but it can cause parents a load of stress and anxiety. Here’s what you need to know to cope.
How often does a breastfed baby need to feed?
Is it every two hours? Three hours? How about overnight?
Here’s a straightforward answer: Constantly.
Okay, so that’s not the case, but that’s what it can feel like for parents caring for a breastfeeding baby who’s in the middle of cluster feeding.
Our sympathies go out to parents who are smack in the middle of cluster feedings. Cluster feeding has lots of causes, but we can reassure you of one thing: You’ll get through this. In the meantime, here’s a breakdown of what’s going on with your baby.
What is cluster feeding?
If your baby feels like they are constantly feeding during a particular time of the day, you might be in the middle of a cluster feed.
Newborn babies already need to eat frequently — usually every 2-3 hours, although sometimes more depending on their needs and your milk supply. But cluster feeding looks — and feels — differently than your regular nursing sessions.
The most straightforward way to understand cluster feedings is that your baby is simply bunching a lot of feedings together in a short time frame. Instead of one meal every few hours, your baby is snacking — a lot!
But cluster feeding is more than just feeding a lot. A baby who is cluster feeding will feed for short periods before unlatching, fussing, nursing more, maybe hiccuping or burping — and so that pattern continues.
If you’ve noticed that your baby is especially attached to you — literally — in the later afternoon and evening, that’s also part of cluster feeding. Staying close to their milk source during this time is imperative for a cluster-feeding babe!
Why do cluster feeds happen?
If you’re in the middle of cluster feeding your baby, you’re probably wondering, “Why on earth is my baby feeding so much?!” (And, maybe, “When will this end?”)
First of all, some babies are simply cluster feeders — they may do it every day, especially when they are very young.
For newborns, one of the benefits of cluster feeding is its positive impact on milk production. The more a baby nurses, the more you produce.
Milk flow is slower at night.
Your primary milk production hormone is prolactin. Prolactin levels tend to be highest in the middle of the night and early morning hours — that’s why waking to feed or pump during your baby’s early weeks is so important for establishing your supply.
The flipside of this is that prolactin levels gradually lower throughout the day. By late afternoon and early evening, your prolactin levels may have lowered enough to slow your milk production.
Because of this, babies need to nurse longer or more often to fill up their tanks.
Another factor? Cluster feeding babies may also drink more to prepare for long stretches of sleeping and growing overnight.
A growth spurt or developmental leap is in the works.
Seeing your baby grow and learn new skills is a delight for parents, but it’s a big job for your baby. And a big job requires a lot of energy.
Your baby will go through numerous growth spurts and developmental leaps during the first year of life. This is true for all babies, regardless of how they are fed. The most common periods happen around 2-3 weeks, 6 weeks, 8 weeks, 3 months, and 6 months.
Remember, though, growth and development can happen at any time — there’s no one-size-fits-all pattern for how your baby will develop.
Nursing is soothing for your baby.
Being a baby is tough work — truly! Your baby’s brain and body are rapidly developing, all while figuring out the world around them. (See above.) What’s more, babies often need help learning how to relax and soothe themselves.
That’s one of the beauties of breast milk. Breast milk is full of hormones that support your baby’s circadian rhythm. For some babies, cluster feeding is a helpful way to boost sleepy, relaxing, restful hormones.
Your baby is teething or sick
Holding and snuggling your baby is certainly comforting, but that alone may not do the trick if your baby isn’t feeling well.
Many babies cluster feed when they’re dealing with a cold or virus — and it makes sense! Your breast milk helps your baby’s immune system fight off illness. What’s more, breastfeeding can help reduce your baby’s pain thanks to the analgesic effects of breast milk.
Interestingly, skin-to-skin contact also can provide pain relief benefits for your baby, which correlates with your baby’s strong desire to be attached to you during cluster feeds.
Cluster feeding and your milk supply
While cluster feeding can be tiring, it can provide a boost to your milk supply if you nurse on demand during this time.
Your milk supply is tailored to your baby’s nutritional demands — precisely tailored to it. So when your baby has a growth spurt or is fighting a cold, cluster feeding can boost your supply to provide enough breast milk for your baby or provide your baby with the antibodies they need to fight off their illness.
How long do babies cluster feed?
Forever?
We know that at 8 pm, after nursing for 3 hours straight, it feels like it may last forever. But we promise — it will not. It absolutely will not last forever.
Usually, cluster feeding resolves within 2-3 days after starting. Also, a few helpful things to remember when cluster feeding is feeling endless:
- Cluster feeding occurs around developmental milestones — your baby’s body is doing important things!
- Over time, your baby will nurse less often, especially as they start consuming more and more solids.

Tips and tricks for managing cluster feeding
1. Keep nursing
We know that you might be tired and frustrated, but it’s important to keep nursing through cluster feedings as much as possible. Your baby’s nursing is helping your supply grow to meet the demands of growth and development.
2. Stay well hydrated and well-fed.
Breastfeeding is thirsty and hungry work. Depending on your milk output, metabolism, and other factors, breastfeeding can burn an additional 300-500 calories a day. Plus, it requires a lot of water to keep producing that milk.
And as far as water goes? The Institute of Medicine advises that breastfeeding parents drink 13 cups of water daily.
However, chugging Big Gulps isn’t necessary. Simply pay close attention to your level of thirst — and when you feel thirsty, drink!
3. Find support and community
Cluster feeding is challenging and can feel endless. (Though it will end, we promise!) But in the meantime, having help will make a massive difference.
Things you can do?
- Create a cluster feeding plan with your partner so you can make evenings more manageable.
- Call on friends for support with meals, chores, and help with older children.
- Connect with other breastfeeding parents through La Leche League, the Latch Lounge, or other breastfeeding communities — it helps to know you’re not alone!
4. Make yourself comfortable
Are you breastfeeding for hours? It can become pretty uncomfortable. Your nipples might be sore. Your arms might ache from holding your baby nonstop. You might feel restless from sitting in the same position.
A few tweaks, though, can make a big difference. Many parents find the side-lying or laid-back positions to be more comfortable if you have to settle in for a long stretch of nursing. Or simply try switching up positions!
Another option is to try babywearing. Babywearing can free you up to move around, which can offer you a much-needed change of pace during the long stretches of nursing. And if you master the art of nursing your baby in a sling or carrier, you’ve got even more options!
And if you master the art of nursing your baby in a sling or carrier, you’ve got even more options!
(But also, don’t pressure yourself! Not all babies or parents love babywearing, so please choose what feels right to you!)
5. Take care of your nipples!
Make sure you take care of your nipples during cluster feeds, as well. Applying nipple butter, lanolin, or even breast milk can help soothe your nipples. Hydrogel pads can also offer relief. Additionally, make sure to air dry your nipples after nursing and choose soft bras and clothing to avoid friction.
And if you use nursing pads? Make sure to change them regularly to avoid the risk of bacterial or fungal infections, especially thrush.
Important note
If you are experiencing ongoing nipple pain, please reach out to an IBCLC! Cluster feeding is hard, but it shouldn’t hurt. Pain can indicate issues with latching, which can lead to problems with milk supply, clogged ducts, mastitis, and more. However, it’s entirely fixable with help from an experienced lactation consultant.
However, it’s entirely fixable with help from an experienced lactation consultant.
6. Make time for yourself
Just like you need to take care of your nipples, you also need to care for yourself. Infant care is a big job, and it’s downright exhausting when you add cluster feeding on top of that.
So find things that can bring you — yes, YOU! — a bit of joy right now. Is it downloading a new book by a favorite author to read while nursing? Rewatching Virgin River for the 10th time?
Accepting help so you can take a quiet walk by yourself? Taking a few minutes to paint your toenails for the first time since you got pregnant? Making a pot of fresh coffee instead of reheating the old stuff?
There are all kinds of ways — both big and small — to make time for yourself. Make sure you do something that brings happiness to your heart!
7. Talk to an IBCLC
Finally, the bit of advice we always offer to parents no matter what kind of breastfeeding situation they’re dealing with: Talk to an IBCLC! IBCLCs can provide invaluable support to parents looking for ways to make breastfeeding work for them and their babies. Never be shy about reaching out!
Never be shy about reaching out!
Your journey, our support
Cluster feeding is tough, but you don’t have to navigate it on your own. Book a convenient online video appointment with a Nest Collaborative IBCLC today.
Learn More About Nest Collaborative
Sign Up For Breastfeeding Tips
How spatially constrained multidimensional clustering works—ArcGIS Pro
When we look at the world around us, we automatically organize, group, differentiate, and classify what we see to better understand the objects around us. This type of mental classification is necessary for learning and understanding. Similarly, you can use the Multivariate Clustering tool to better explore your data. Using the number of clusters created, the tool looks for a solution in which all objects in each cluster are as similar as possible, and the groups themselves are as different from each other as possible. Feature similarity is based on a set of attributes specified for the Fields of Analysis parameter, which can optionally impose limits on the size of the cluster. The algorithm of this tool uses a connectivity graph (Minimum Spanning Tree) and the SKATER method to find natural clusters in your data, as well as evidence accumulation to estimate the likelihood of cluster membership.
The algorithm of this tool uses a connectivity graph (Minimum Spanning Tree) and the SKATER method to find natural clusters in your data, as well as evidence accumulation to estimate the likelihood of cluster membership.
Hint:
Clustering, grouping, and classification are the most commonly used machine learning techniques. The Spatially Constrained Multivariate Clustering tool uses "no training" processing techniques to find natural clusters in your data. These classification methods are called "no training" classification because they do not require a set of pre-classified objects to "train" the algorithm to further find clusters in your data.
Although there are many cluster analysis algorithms, all of them are classified as NP-hard. This means that the only way to ensure that the solution ideally maximizes the similarities within the group and the differences between the groups is to try all possible combinations of objects that need to be clustered. Although this can be achieved with a small number of objects, the task quickly becomes intractable.
Not only is it impossible to find an optimal solution, but it is also impossible to determine a grouping algorithm that will work best for all possible scenarios. Clusters come in different shapes, sizes and densities. Attributes can contain data with different ranges, symmetry, continuity, and units. This explains why so many different clustering algorithms have been developed over the past 50 years. The Spatially Constrained Multivariate Clustering tool should be viewed as an exploratory tool to learn more about the structures in your data.
Possible applications
Some ways to use this tool are listed below:
- If you have collected animal observation data to better understand their habitat, the Spatially Constrained Multivariate Clustering tool can be useful here. Knowledge of where and when salmon schools congregate, for example, can help design protected areas to ensure successful spawning.
- Agronomists may need to classify different types of soil in a study area.
 Using the Spatially Constrained Multivariate Clustering tool with soil characteristics derived from a number of samples, clusters of different, spatially continuous soil types can be identified.
Using the Spatially Constrained Multivariate Clustering tool with soil characteristics derived from a number of samples, clusters of different, spatially continuous soil types can be identified. - By grouping customers based on buying preferences, demographics, and movement patterns, you can create an effective marketing strategy for your company's products.
- City planners often need to divide cities into districts in order to efficiently locate municipal offices and develop local communities. Using the Spatially Constrained Multivariate Clustering with Physical and Demographic Characteristics of City Blocks tool, city planners can identify spatially contiguous areas of a city with similar physical and demographic characteristics.
- Environmental error is a well-known statistical influence problem when performing analysis on aggregated data. Often, the aggregation scheme used for analysis has nothing to do with what needs to be analyzed.
 Census data, for example, is aggregated based on population distribution, which may not be the best option for wildfire analysis. Breaking down the smallest units of aggregation into homogeneous regions with a set of attributes that accurately reflect analytical objectives is an effective technique to reduce the impact of aggregation and avoid environmental error.
Census data, for example, is aggregated based on population distribution, which may not be the best option for wildfire analysis. Breaking down the smallest units of aggregation into homogeneous regions with a set of attributes that accurately reflect analytical objectives is an effective technique to reduce the impact of aggregation and avoid environmental error.
Input
This tool accepts point or polygon input features, a path to an Output Feature Class, one or more Analysis Fields, an integer value for the Number of Clusters to create, and a Spatial Constraint type to apply with the grouping algorithm. There are also several additional options that are used to set the Cluster Size Limits to either the minimum or maximum number of objects in a cluster, or the minimum or maximum sum of cluster attributes, and the Optimal Number of Clusters Estimation Output Table.
Analysis fields
Select numeric fields that represent relative, interval, or ordinal measurement systems. Although nominal data can be represented using binary variables, this usually does not work as well as other numeric variable types. For example, you could create a Rural variable and assign each feature (for example, each adjacent census block) a value of 1 if it's a rural feature, or a value of 0 if it's an urban feature. The best example of applying this variable with the Spatially Constrained Multivariate Clustering tool is the amount or fraction of agricultural area associated with each feature.
Although nominal data can be represented using binary variables, this usually does not work as well as other numeric variable types. For example, you could create a Rural variable and assign each feature (for example, each adjacent census block) a value of 1 if it's a rural feature, or a value of 0 if it's an urban feature. The best example of applying this variable with the Spatially Constrained Multivariate Clustering tool is the amount or fraction of agricultural area associated with each feature.
The values in the Analysis Fields are standardized by the tool because variables with high variability (large distribution of relative mean data) appear to have a greater effect on clustering than variables with low variance. Attribute value standardization involves a z-transform where the average of all values is subtracted from each value and divided by the standard deviation computed for all values. Standardization puts all these attributes on the same scale, even when they are represented by completely different types of numbers: coefficients (from 0 to 1. 0), population (a value over 1 million), and distances (for example, kilometers).
0), population (a value over 1 million), and distances (for example, kilometers).
You must select variables that you think will distinguish one cluster of objects from another. Let's say you want to group school districts by student performance on standardized tests. You can select Analysis fields such as overall test scores, results for each subject such as math or literature, the percentage of students who achieved the minimum mark on a test, and so on. When you run the Spatially Restricted Multivariate Clustering tool, an R value is calculated for each variable 2 and sent to the message box. In the summary below, school districts are grouped based on student test scores, percentage of adults who did not graduate from high school, cost per student, and average student-teacher ratio. Note that the variable TestScores has the highest value R 2 . This means that this variable most effectively clusters school districts. The R value of 2 reflects the extent to which variation in the original TestScores data was preserved during the grouping process. The more R 2 for a particular variable, the better the variable distinguishes between your objects.
The more R 2 for a particular variable, the better the variable distinguishes between your objects.
More details:
R 2 is calculated as follows:
(TSS - ESS) / TSS
Where TSS is the total sum of squares and ESS is the explained sum of squares. TSS is calculated by squaring and summing the deviations from the global mean for the variable. ESS is calculated in the same way, only deviations are applied across groups: each value is subtracted from the average value for the group to which it belongs, and then squared and summed.
Cluster size limits
The cluster size is determined by the Cluster size limits setting. You can set a minimum or maximum threshold for a cluster. The size limit can be either the Number of features in each cluster or the sum of the Attribute Values. For example, if you're clustering US counties based on a set of economic variables, you might specify that each cluster has a minimum population of 5 million and a maximum population of 25 million.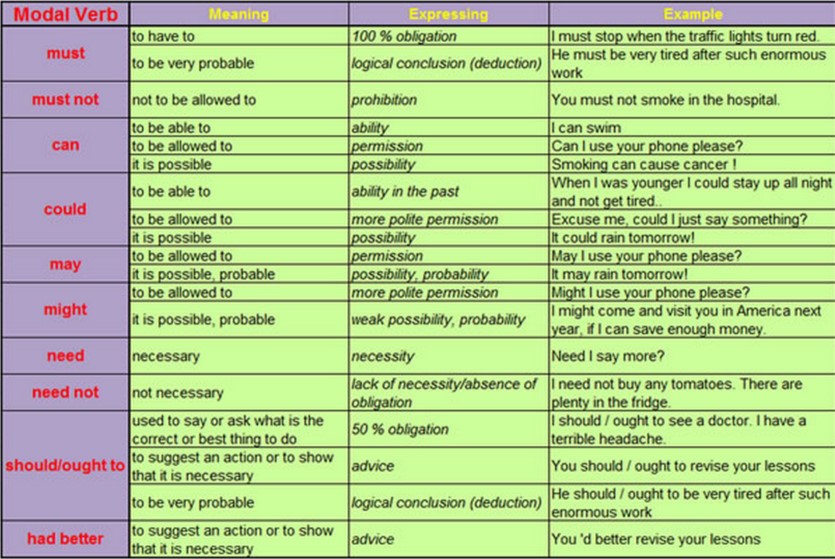 Or you can specify that each cluster can have at least 30 counties.
Or you can specify that each cluster can have at least 30 counties.
If the Maximum number per cluster constraint is set, the algorithm will start with one cluster and split it into adjacent clusters with similar values. New clusters will be created until the sizes of all clusters are less than the maximum number for the cluster, taking into account all variables for splitting.
SKATER forms clusters by splitting data with values close to the objects of interest. It is possible that the Cluster Size Limit will not be met for all clusters. This can happen when the cluster size constraints did not lead to the creation of optimal clusters
SKATER forms clusters by spatially splitting data with close values of all specified Analysis Fields. It is possible that the Cluster Size Limit will not be met for all clusters. This may be because the maximum and minimum limits were set to close values, or because of the way the minimum spanning tree is created based on spatial constraints. In this case, the tool will stop working and information about clusters that do not meet the specified requirements will appear in the message window.
In this case, the tool will stop working and information about clusters that do not meet the specified requirements will appear in the message window.
Number of clusters
Sometimes you may know exactly the number of clusters that best suits your task. For example, if you have five sales reps and you want to assign each of them their own region, you would use a value of 5 for the Number of Clusters parameter. But in many cases the criterion for choosing the exact number of clusters is not available. Instead, you need to get the number that best categorizes the similarities and differences between objects. In this situation, you can leave the Number of Clusters blank and let Spatially Constrained Multivariate Clustering evaluate the efficiency of dividing features into 2, 3, 4, and up to 30 groups. Clustering efficiency is measured using the pseudo-F-statistic of Kalinske-Harabasz, which is the ratio of the variation between clusters to the variation within a cluster: In other words, the ratio of the similarity of objects within a group to the difference between objects between groups is:
Suppose you want to create four contiguous clusters. In this case, the tool will create a minimum spanning tree that reflects both the spatial structure of your features and their associated analysis field values. The tool will then determine the best place to cut the tree to produce two separate clusters. Next, he will determine which of the two resulting clusters should be divided to obtain three groups in the best way. One of the two clusters will be split, the other will remain unchanged. Finally, it will determine which of the three resulting clusters should be split to get the four best clusters. At each division, the best solution is the one that increases the similarity within the clusters and the difference between them. A cluster can no longer be split (except for arbitrary division) when the values of the analysis fields of all objects within the cluster are identical. In the event that all resulting clusters have identical features, the Spatially Constrained Multidimensional Clustering tool stops creating new clusters, even if the specified Number of Clusters is not reached.
In this case, the tool will create a minimum spanning tree that reflects both the spatial structure of your features and their associated analysis field values. The tool will then determine the best place to cut the tree to produce two separate clusters. Next, he will determine which of the two resulting clusters should be divided to obtain three groups in the best way. One of the two clusters will be split, the other will remain unchanged. Finally, it will determine which of the three resulting clusters should be split to get the four best clusters. At each division, the best solution is the one that increases the similarity within the clusters and the difference between them. A cluster can no longer be split (except for arbitrary division) when the values of the analysis fields of all objects within the cluster are identical. In the event that all resulting clusters have identical features, the Spatially Constrained Multidimensional Clustering tool stops creating new clusters, even if the specified Number of Clusters is not reached. When all Analysis Fields have identical values, there is no reason to split the cluster.
When all Analysis Fields have identical values, there is no reason to split the cluster.
Spatial constraints
The Spatial constraints parameter allows you to be sure that the resulting clusters will be spatially close. The Adjacency options are enabled for polygon feature classes and specify that features can only be in the same cluster if they share an edge (Coincident Edges Only, or an edge or vertex (Coincident Edge Corners) with another cluster member. The Polygon Continuity options are not very good choice, but if the dataset contains clusters of non-contiguous polygons, or polygons with no adjacent neighbors.0003
The Advanced Delaunay interpolation option is suitable for point and polygon features and allows you to be sure that a feature is included in a cluster only if at least one other feature is a natural neighbor (Delaunay triangulation). Conceptually, the Delaunay triangulation method creates a network of non-overlapping triangles based on feature centroids. Each object is a triangle node, and nodes with common edges are considered neighbors. These triangles are then trimmed with a convex polygon so that objects do not coexist with objects outside of this polygon. The option should not be used for datasets with matching features. Also, because the Delaunay triangulation method converts features to Thiessen polygons to determine neighbor relationships, especially when there are polygon features and sometimes peripheral features in the dataset, the results of using this option may not always be as expected. In the image below, notice that some of the source polygon groups are not contiguous. However, when they are converted to Thiessen polygons, all grouped features actually have adjacent edges.
Each object is a triangle node, and nodes with common edges are considered neighbors. These triangles are then trimmed with a convex polygon so that objects do not coexist with objects outside of this polygon. The option should not be used for datasets with matching features. Also, because the Delaunay triangulation method converts features to Thiessen polygons to determine neighbor relationships, especially when there are polygon features and sometimes peripheral features in the dataset, the results of using this option may not always be as expected. In the image below, notice that some of the source polygon groups are not contiguous. However, when they are converted to Thiessen polygons, all grouped features actually have adjacent edges.
For Delaunay triangulation, the adjacency of the Thiessen polygons defines the neighbor relationship.
If the resulting groups should be close in space and time, create a Spatial Weights Matrix (SWM) file using the Build Spatial Weights Matrix tool and select Spatiotemporal Window for Define Spatial Relationships. You can then specify the SWM file that you created with the Build Spatial Weights Matrix tool in the Weight Matrix File parameter when you run the Spatially Constrained Multivariate Clustering tool.
You can then specify the SWM file that you created with the Build Spatial Weights Matrix tool in the Weight Matrix File parameter when you run the Spatially Constrained Multivariate Clustering tool.
Although spatial relationships between features are stored in the SWM file and used by the Spatially Constrained Multivariate Clustering tool to impose spatial constraints, no actual weighting occurs. The SWM file is only used to keep track of which objects can and cannot be included in the same cluster.
Minimum spanning tree
When specifying a spatial constraint to include contiguous or nearby features in a group, the tool first generates a connectivity graph representing the neighbor relationships of the features. On the basis of the connectivity graph, a minimum spanning tree is formed, which reflects both the spatial relationships of objects and the similarity of these objects. The objects become nodes in a minimum spanning tree connected by weighted edges. The weight of each edge is proportional to the similarity of the features it connects. After the creation of the minimum spanning tree, the branch (edge) of the tree is truncated, after which we get two minimum spanning trees. The truncated edge is chosen so as to minimize the discrepancy in the resulting clusters, while avoiding obtaining clusters consisting of a single object. At each iteration, one of the minimum spanning trees is divided by this pruning process until the specified Number of Clusters is obtained. The published method is called SKATER (spatial cluster analysis with tree edge removal). Although each iteration chooses a branch that optimizes the similarity of the objects in the group, there is no guarantee that the end result will be optimal.
After the creation of the minimum spanning tree, the branch (edge) of the tree is truncated, after which we get two minimum spanning trees. The truncated edge is chosen so as to minimize the discrepancy in the resulting clusters, while avoiding obtaining clusters consisting of a single object. At each iteration, one of the minimum spanning trees is divided by this pruning process until the specified Number of Clusters is obtained. The published method is called SKATER (spatial cluster analysis with tree edge removal). Although each iteration chooses a branch that optimizes the similarity of the objects in the group, there is no guarantee that the end result will be optimal.
Participation Probability
The Membership Probability Permutation parameter specifies the number of permutations required to calculate the membership probability by evidence accumulation. Membership probabilities will be included in the output feature class in the PROB field. A high membership probability means that the object is similar and close to the cluster to which it is assigned, and you can be sure that the object belongs to the cluster. A low probability indicates that the object is very different from the cluster to which it was assigned by the SKATER algorithm, or the object should be included in a different cluster if the Fields of Analysis, Cluster Size Constraints, or Spatial Constraints have changed.
A low probability indicates that the object is very different from the cluster to which it was assigned by the SKATER algorithm, or the object should be included in a different cluster if the Fields of Analysis, Cluster Size Constraints, or Spatial Constraints have changed.
The number of permutations you specify determines the number of spanning trees created to violate the SKATER space constraint. Then the algorithm works for the given Number of clusters for each random spanning tree. Using the clusters defined by the SKATER algorithm, the permutation process keeps track of how often cluster members merge as spanning trees change. Entities that change clusters due to small spanning tree changes get low membership probabilities, while objects that don't change clusters get high membership probabilities.
Calculating such probabilities for large datasets can be quite time consuming. It is recommended to first make several attempts and determine the optimal number of clusters for analysis, and then, at the next start, calculate the probabilities. You can improve performance by increasing the Parallel Settings value to 50.
You can improve performance by increasing the Parallel Settings value to 50.
Output
The number of output features generated by Spatially Constrained Multivariate Clustering. Messages can be viewed in the Geoprocessing pane by hovering over the progress bar, clicking the tool's progress bar button, or by expanding the messages section at the bottom of the Geoprocessing pane. You can access the messages for the Spatially Constrained Multivariate Clustering tool you ran earlier in the Geoprocessing History pane.
The default result of the Spatially Restricted Multidimensional Clustering tool is a new output feature class containing the fields used in the analysis, as well as a new integer field CLUSTER_ID containing information about which cluster each feature belongs to. This output feature class is added to the table of contents with a unique display color scheme that is applied to the CLUSTER_ID field.
Output of Spatially Constrained Multivariate ClusteringSpatially Constrained Multivariate Clustering Output Charts
Several types of charts are generated to summarize the created clusters. Box plots are used to show information about each of the clusters as well as about each analysis variable. Below is an image that will help you analyze the box plots and their total values for each Analysis Field and cluster created: minimum data value, 1 th quartile, global median value, 3 and quartile, the maximum value of the data, and outliers in the data (values less than or greater than 1.5 times the interquartile range). Hover over the box plot to see these values, as well as the interquartile range value. All ticks outside the top or bottom box (not between the minimum and maximum) are outliers in the data.
Box plots are used to show information about each of the clusters as well as about each analysis variable. Below is an image that will help you analyze the box plots and their total values for each Analysis Field and cluster created: minimum data value, 1 th quartile, global median value, 3 and quartile, the maximum value of the data, and outliers in the data (values less than or greater than 1.5 times the interquartile range). Hover over the box plot to see these values, as well as the interquartile range value. All ticks outside the top or bottom box (not between the minimum and maximum) are outliers in the data.
More details:
Interquartile range (IQR) - the difference between 3 m and 1 m quartile. Low outliers are values less than 1.5*IQR (Q1-1.5*IQR) and high outliers are values greater than 1.5*IQR (Q3+1.5*IQR). Outliers appear on boxplots as dot symbols.
The Parallel Box Plot provides a summary of the clusters and the variables within them. For example, a spatially constrained multivariate clustering tool was launched in census tracts to create four clusters. Note. That, in the image below, cluster 2 (red) corresponds to the tracts with the average rent, the highest homeownership values for women with children (FHH_CHILD), the highest number of dwellings (HSE_UNITS), and the highest number of children under 5 years of age. Cluster 2 (golden yellow) corresponds to areas with high average rents, a fairly low number of households by women with children, and a fairly high number of dwellings. Cluster 3 (green) corresponds to the tracts with the lowest number of households by women with children, the lowest number of children under 5 years of age, the minimum number of dwellings and the low level of rent (but higher than in cluster 1). Hover over each node of the midlines to see the cluster mean for each Field of Analysis.
For example, a spatially constrained multivariate clustering tool was launched in census tracts to create four clusters. Note. That, in the image below, cluster 2 (red) corresponds to the tracts with the average rent, the highest homeownership values for women with children (FHH_CHILD), the highest number of dwellings (HSE_UNITS), and the highest number of children under 5 years of age. Cluster 2 (golden yellow) corresponds to areas with high average rents, a fairly low number of households by women with children, and a fairly high number of dwellings. Cluster 3 (green) corresponds to the tracts with the lowest number of households by women with children, the lowest number of children under 5 years of age, the minimum number of dwellings and the low level of rent (but higher than in cluster 1). Hover over each node of the midlines to see the cluster mean for each Field of Analysis.
After learning the basics about parallel box plot analysis, you can explore the box plots of each cluster for each variable by selecting Near on the Series tab of the Chart Properties panel. In this view of the data, it is easy to see which group has the largest and smallest range of values for each variable. A box plot will be created for each variable of each cluster, and you can see how the values of all clusters are related to each other. Place the cursor over the boxplot of each variable to see the minimum, maximum, and mean value for each variable in each cluster. In the chart below, you will see that Cluster 4 (golden) has the highest MEDIANRENT values and contains areas ranging from 354 to 813.
In this view of the data, it is easy to see which group has the largest and smallest range of values for each variable. A box plot will be created for each variable of each cluster, and you can see how the values of all clusters are related to each other. Place the cursor over the boxplot of each variable to see the minimum, maximum, and mean value for each variable in each cluster. In the chart below, you will see that Cluster 4 (golden) has the highest MEDIANRENT values and contains areas ranging from 354 to 813.
A bar chart is also created showing the number of objects in the clusters. Selecting each column will also select features on the map, which can help you to perform further analysis.
If you leave the Number of Clusters parameter blank, the tool will calculate the optimal number of clusters for your data. If you specify a path for the Cluster Estimation Output Table, a chart will be created with the calculated values of the Pseudo-F statistic.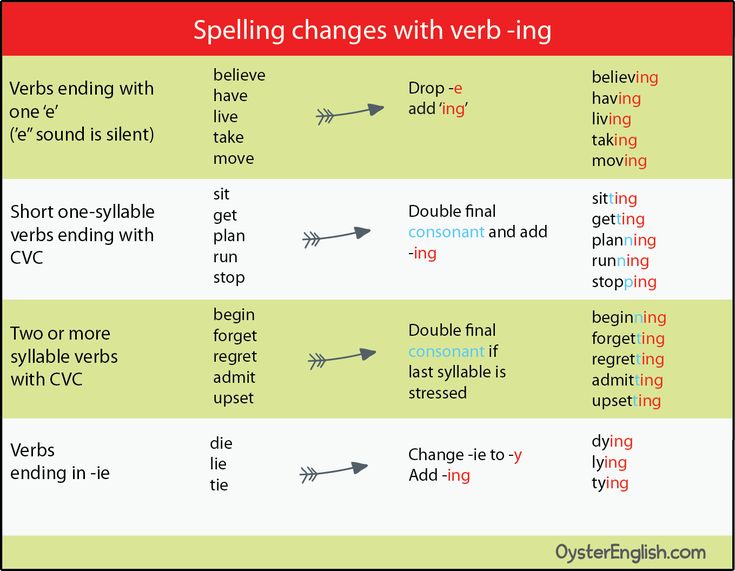 The highest peak of the graph is the largest F-statistic, indicating the most efficient number of groups to distinguish between the specified objects and variables. In the following plot, the F-statistic associated with the four groups has the highest value. Five groups with a large pseudo-F statistic would also be a good choice.
The highest peak of the graph is the largest F-statistic, indicating the most efficient number of groups to distinguish between the specified objects and variables. In the following plot, the F-statistic associated with the four groups has the highest value. Five groups with a large pseudo-F statistic would also be a good choice.
Recommendation
While there is a tendency to include as many Analysis Fields as possible, it is best to start with a single variable when using the Spatially Constrained Multivariate Clustering tool. The results are much easier to interpret with fewer fields of analysis. It is also easier to determine which variables separate groups better with fewer fields.
In many situations, you will run the Spatially Constrained Multivariate Clustering tool several times looking for the optimal Number of Clusters, the most effective Spatial Constraints, and the combination of Fields of Analysis that best group your features.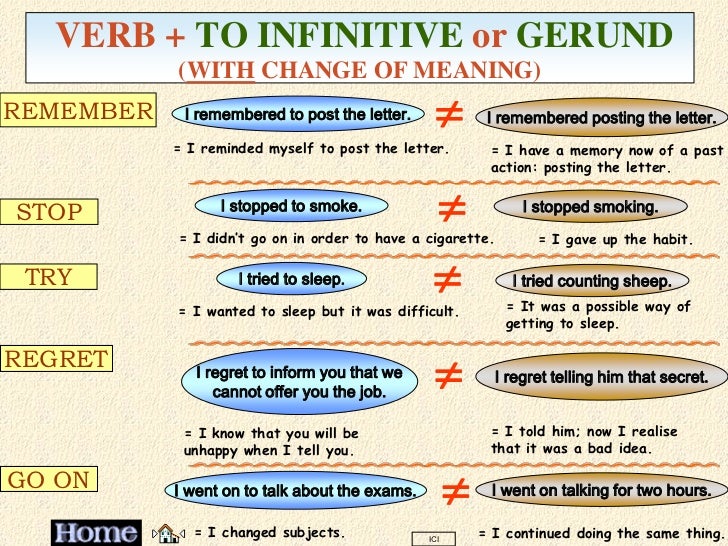
If the tool returns 30 as the optimal number of clusters, look at the F-statistic chart. Choosing the number of clusters and interpreting the F-statistic plot is a skill, and it's possible that a smaller number of clusters would be more appropriate for your analysis.
Additional sources
Duque, J. C., R. Ramos, and J. Surinach. 2007. "Supervised Regionalization Methods: A Survey" in International Regional Science Review 30: 195–220.
Assuncao, R. M., M. C. Neves, G. Camara, and C. Da Costa Freitas. 2006. "Efficient Regionalization Techniques for Socio-Economic Geographic Units Using Minimum Spanning Trees" in International Journal of Geographical Information Science 20(7): 797–811.
Feedback on this section?
Cluster management - Azure Databricks
- Article
- Reading takes 14 minutes
This article describes how to manage Azure Databricks clusters, including display, edit, startup, shutdown, delete, access control, and performance monitoring and logs.
Cluster display
Note
This article describes the deprecated cluster user interface. For more information about the preview user interface, including terminology changes for cluster access modes, see Create a Cluster. For a comparison of new and legacy cluster types, see Cluster UI Changes and Cluster Access Modes.
To display clusters in the workspace, click Calculations in the sidebar.
The Calculations page displays clusters on two tabs: Universal Clusters and Job Clusters .
On the left side there are two columns indicating whether the cluster is pinned and its status:
- Pinned
- Starting up, shutting down
- Standard cluster
- In progress
- Job completed
- High Concurrency Cluster
- Working
- Job completed
- Access denied
- Working
- Job completed
- Table access control lists are enabled
- Working
- Job completed
On the right side of the tab Generic Clusters is an icon that you can use to shut down the cluster.
You can use the three-button menu to restart, clone, delete a cluster, or change its permissions. Menu options that are not available will be grayed out.
The Generic Clusters tab displays the number of notebooks connected to the cluster.
Filtering the list of clusters
You can filter the lists of clusters using the buttons and the search field in the upper right corner:
Pinning a cluster
The cluster will be permanently deleted 30 days after it ends. To keep the configuration of a generic cluster even if it is more than 30 days old, an administrator can pin the cluster. You can pin up to 100 clusters.
You can pin a cluster to the cluster list or cluster details page:
Pin a cluster to the cluster list
To pin or unpin a cluster, click the pin icon to the left of the cluster name.
Pinning a cluster on the cluster details page
To pin or unpin a cluster, click the pin icon to the right of the cluster name.
You can also call the pinning API endpoint to programmatically pin the cluster.
Viewing the cluster configuration as a JSON file
Sometimes it can be useful to view the cluster configuration in JSON format. This is especially useful if you want to create similar clusters using the Cluster API 2.0. When viewing an existing cluster, simply go to the Configuration tab, click the JSON item in the top right, copy the JSON and paste it into the API call. The JSON representation is read-only.
Cluster modification
Cluster configuration is edited on the cluster details page. To display the cluster details page, click the cluster name on the Calculations page.
You can also use the edit API endpoint to change the cluster programmatically.
Note
- Notebooks and tasks connected to the cluster remain connected after editing.
- Libraries installed in the cluster remain installed after editing.
- If any attribute of a running cluster changes (except cluster size and permissions), it must be restarted. This may break the experience for users who are currently using the cluster.
- Only running and shutdown clusters can be edited. But on the cluster details page, you can update permissions for clusters that are in other states.
For detailed information about the cluster configuration properties that you can change, see Configuring Clusters.
Cloning a cluster
You can create a new cluster by cloning an existing one.
In the list of clusters, click the three-button menu and select Clone from the drop-down list.
On the cluster details page, click and select Clone from the drop-down list.
The form for creating a cluster opens, in which the cluster configuration fields are pre-filled. The following attributes from an existing cluster are not included in the clone:
- Cluster permissions
- Installed libraries
- Connected notebooks
Managing cluster access
Managing cluster access using the Administration Console allows administrators and authorized users to grant granular access to the cluster to other users. There are two types of cluster access control:
There are two types of cluster access control:
-
Permission to create a cluster. Administrators can select which users are allowed to create clusters.
-
Cluster level permissions. A user who has Manage permission for a cluster can specify whether other users can connect to, restart, resize, and manage the cluster from the cluster list or the cluster details page.
In the list of clusters, click the three button menu (/_static/images/clusters/cluster-3-buttons.png) and select Change permissions .
On the cluster details page, click and select Permissions .
To learn how to configure cluster access control and permissions at the cluster level, see Manage cluster access.
Starting a cluster
In addition to creating a new cluster, you can also start a cluster that has been terminated. This allows you to re-create a failed cluster with its original configuration.
The cluster can be started from the list of clusters, from the cluster details page, or from a notebook.
-
Click the arrow to start the cluster from the list of clusters:
-
To start the cluster on the cluster details page, click Start :
-
To start a cluster from a notebook, click the Connect drop-down box above the notebook. From this list, you can select a cluster to connect to the notebook.
You can also call the startup API endpoint to programmatically start the cluster.
Azure Databricks identifies a cluster using a unique cluster ID. When starting a shutdown cluster, Databricks recreates the cluster with the same ID, automatically installs all libraries, and remounts the notebooks.
Note
If you are using a trial workspace and the trial has expired, you will not be able to start the cluster.
Cluster autostart for jobs
If a job assigned to an existing cluster that was terminated by is scheduled to run, or a connection is made to the terminated cluster from the JDBC/ODBC interface, the cluster is automatically restarted. See Creating a Job and Connecting JDBC.
See Creating a Job and Connecting JDBC.
Cluster autostart allows you to configure clusters to automatically shut down, so you don't have to manually restart clusters for scheduled jobs. You can also schedule cluster initialization by scheduling a job on the cluster that was shut down.
The access control permissions for the cluster and the job are checked before automatically restarting the cluster.
Note
If the cluster was created on Azure Databricks version 2.70 or earlier, autostart will not occur: jobs scheduled on clusters that have shut down will fail.
Shutting down the cluster
You can shut down the cluster to conserve the resources of the cluster. A cluster that shuts down cannot run notebooks or jobs, but its configuration is saved so that it can be reused later (or, in the case of some job types, automatically started). You can manually shut down the cluster or set it to shut down automatically after a specified period of inactivity. Azure Databricks records information about each cluster shutdown. If the number of clusters that have completed work exceeds 150, the oldest clusters are deleted.
Azure Databricks records information about each cluster shutdown. If the number of clusters that have completed work exceeds 150, the oldest clusters are deleted.
If the cluster is not pinned, it is automatically deleted after 30 days from shutdown and cannot be recovered.
Completed clusters appear in the list of clusters with a gray circle to the left of the cluster name.
Note
When starting a job on a new job cluster (generally recommended), the cluster shuts down and becomes unrestartable after the job has completed. On the other hand, if you schedule the job to run at existing generic cluster that has been shut down, that cluster will start automatically.
Important!
If you are using a premium trial workspace, all running clusters will be terminated in the following cases:
- When you upgrade your workspace to a full premium plan.
- If the workspace is not up to date and the trial has expired.

Manual shutdown
You can manually shut down a cluster from the list of clusters or from the cluster details page.
-
To end the cluster in the list of clusters, click the square:
-
To end the cluster on the cluster details page, click End :
Automatic termination
You can also set the cluster to terminate automatically. During cluster creation, you can specify a period of inactivity, in minutes, after which the cluster should be shut down. If the difference between the current time and the time the command was last run on the cluster exceeds the specified period of inactivity, Azure Databricks automatically shuts down that cluster.
A cluster is considered inactive when all commands in the cluster, including Spark jobs, structured streaming, and JDBC calls, have completed.
Warning
- Clusters do not report activities caused by using DStreams.
 This means that auto-shutdown may cause the cluster to abort while DStreams is running. Disable auto-shutdown for clusters running DStreams, or consider using structured streaming.
This means that auto-shutdown may cause the cluster to abort while DStreams is running. Disable auto-shutdown for clusters running DStreams, or consider using structured streaming. - The auto-shutdown feature only monitors Spark jobs, not user-defined local processes. Thus, if all Spark jobs are terminated, the cluster may be terminated even if local processes are still running.
- Idle state clusters continue to accumulate DBU and Cloud Instance fees during the period of inactivity until they are terminated.
Automatic shutdown setting
To configure automatic shutdown, use field Automatic shutdown in field Autopilot settings on the cluster creation page:
Important!
The default auto-terminate setting depends on whether you choose to create a standard cluster or a highly parallel cluster:
- Standard clusters are set to auto-terminate after 120 minutes.
- High concurrency clusters are configured not to shut down automatically .
You can opt out of automatic shutdown by unchecking the corresponding checkbox or specifying a period of inactivity 0 .
Note
Latest versions of Spark provide the best support for automatic shutdown. Older versions of Spark have known limitations that may cause cluster activity reports to be inaccurate. For example, clusters running JDBC, R, or streaming commands may report expired expiration times, which could cause the cluster to terminate prematurely. Update to the latest version of Spark to take advantage of auto-shutdown fixes and improvements.
Unexpected shutdown
Sometimes a cluster shuts down unexpectedly and not because a manual or configured automatic shutdown has worked.
See the Knowledge Base for a list of shutdown reasons and corrective actions.
Deleting a cluster
Deleting a cluster terminates the cluster and deletes its configuration.
Warning
This action cannot be undone.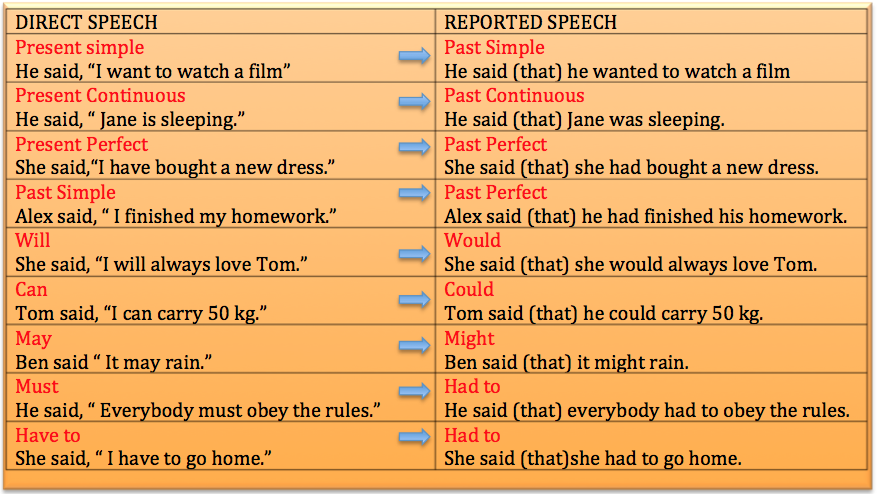
Cannot delete a pinned cluster. To remove a pinned cluster, an administrator must first unpin it.
In the list of clusters, click the three-button menu and select Delete from the drop-down list.
On the cluster details page, click and select Delete from the drop-down list.
You can also call the hard delete API endpoint to programmatically delete a cluster.
Restarting the cluster to update it with the latest images
Restarting the cluster gets the latest images for the compute containers and virtual machine hosts. It is especially important to schedule regular restarts for long-running clusters that are used frequently for some applications, such as streaming data processing.
You must take care of regular restarts of computing resources to ensure that the image versions are up to date.
Important!
If you enable a security compliance profile for an account or workspace, long-running clusters will automatically restart after 25 days. Databricks recommends that administrators restart clusters earlier than 25 days during the scheduled maintenance window. This reduces the risk of an automatic restart interrupting a scheduled job.
Databricks recommends that administrators restart clusters earlier than 25 days during the scheduled maintenance window. This reduces the risk of an automatic restart interrupting a scheduled job.
There are several ways to restart the cluster:
- Use the user interface to start the cluster from the cluster details page. To display the cluster details page, click the cluster name on the Calculations page. Select item Restart .
- Use the Cluster API to restart the cluster.
- Use a script provided by Azure Databricks that determines how long clusters will run and optionally restarts them if the specified number of days have passed since they started.
Run a script that determines how many days clusters run, and restart clusters if necessary days. Azure Databricks provides this script as a notebook.
The first lines of the script define the configuration options:
-
min_age_output: The maximum number of days the cluster can run. Default value: 1.
Default value: 1. -
perform_restart: Ifis True, the script restarts clusters that are older than the number of days specified inmin_age_output. The default value isFalse; that is, the parameter detects long-running clusters, but does not restart them. -
secret_configuration: ReplaceREPLACE_WITH_SCOPEandREPLACE_WITH_KEYwith the secret scope and key name. For more information about configuring secrets, see the notebook.
Warning
If perform_restart is set to True , the script automatically restarts the affected clusters, which can cause active jobs to fail and open notebooks to be reset. To reduce the risk of business-critical workspace jobs being interrupted, define a scheduled maintenance period and be sure to notify workspace users.
Notebook for identifying and (if necessary) restarting long-running clusters
Get notebook
Detailed information about Spark jobs can be viewed in the Spark user interface, which can be accessed from the corresponding tab on the cluster details page.
You can get information about active and terminated clusters.
When restarting a cluster that has shut down, the Spark UI displays information about the restarted cluster rather than the log data for the cluster that shut down.
Viewing cluster logs
Azure Databricks provides three types of logging of cluster-related activities:
This section discusses cluster event logs and driver and worker logs. For more information about init script logs, see Init Script Logs.
Cluster event logs
The cluster event log displays important cluster lifecycle events that were triggered manually by user action or automatically triggered by Azure Databricks action. Such events affect both the operation of the cluster as a whole and the jobs running in the cluster.
See ClusterEventType REST API data structure for supported event types.
Events are stored for 60 days, which is comparable to other data stored in Azure Databricks.
Viewing the cluster event log
-
Click Calculation in the sidebar.
-
Click the cluster name.
-
Click the Event Log tab.
To filter events, click in the field Filter by event type… and check the boxes for one or more event types.
Use the Select All command to simplify filtering by excluding certain types of events.
View event details
For more information about an event, click its line in the log, and then click the JSON tab.
Cluster 9 driver and worker logs0033
Direct print and log instructions from notebooks, jobs, and libraries point to Spark driver logs. These logs have three types of output:
- Standard output
- Standard error
- log4j logs
These files can be accessed from the Logs tab of the driver on the cluster details page. To download a log file, click on its name.
To download a log file, click on its name.
You can use the Spark user interface to view Spark worker logs. You can also configure the log shipping location for the cluster. Worker logs and cluster logs are delivered to the specified location.
Performance monitoring
To help you monitor the performance of your Azure Databricks clusters, Azure Databricks provides access to Ganglia metrics from the cluster details page.
You can also configure an Azure Databricks cluster to send metrics to a Log Analytics workspace in Azure Monitor (a monitoring platform for Azure).
Datadog agents can be installed on cluster nodes to send Datadog metrics to a Datadog account.
Ganglia Metrics
To access the Ganglia user interface, go to the Metrics tab on the cluster details page. CPU metrics are available in the Ganglia UI for all Databricks runtimes. GPU metrics are available for GPU-enabled clusters.
Click the link Ganglia User Interface to view dynamic metrics.
Click the snapshot file to view historical metrics. The snapshot contains aggregated metrics for the hour prior to the selected time.
Setting up a metrics collection
By default, Azure Databricks collects Ganglia metrics every 15 minutes. To configure the collection period, set the environment variable DATABRICKS_GANGLIA_SNAPSHOT_PERIOD_MINUTES using the initialization script, or in field spark_env_vars in the Create Cluster API.
Azure Monitor
An Azure Databricks cluster can be configured to send metrics to a Log Analytics workspace in Azure Monitor, the Azure monitoring platform. For complete instructions, see Monitoring Azure Databricks.
Note
If you deployed an Azure Databricks workspace in your virtual network and configured network security groups (NSG) to deny all outbound traffic that is not required by Azure Databricks, you must configure an additional outbound rule for the AzureMonitor service tag.
Datadog Metrics
Datadog agents can be installed on cluster nodes to send Datadog metrics to a Datadog account. The following notebook shows how to install the Datadog agent on a cluster using an initialization script that is cluster-wide.
To install the Datadog agent on all clusters, use the global init script after testing the initialization script with the cluster as scope.
Install Datadog Agent Provisioning Script Notebook
Get Notebook
Decommission Spot VMs
Note
This feature is available in Databricks Runtime 8.0 and later.
Because Spot VM Instances can reduce costs, clusters are typically created using Spot VM instances rather than on-demand instances to run jobs. However, point VM instances can be preempted by the cloud provider's scheduling mechanisms. Preempting spot VM instances can cause problems with running jobs, including:
- Random data retrieval failures
- Loss of random data
- Data Loss RDD
- Job failures
To resolve these issues, you can enable decommissioning. The decommissioning takes advantage of the notification that the cloud provider typically sends before decommissioning a spot VM instance. When a spot VM instance containing an executor receives a preemption notification, the decommissioning process will attempt to transfer random data and RDD data to healthy executors. It usually takes between 30 seconds and 2 minutes before the final charge, depending on the cloud provider.
The decommissioning takes advantage of the notification that the cloud provider typically sends before decommissioning a spot VM instance. When a spot VM instance containing an executor receives a preemption notification, the decommissioning process will attempt to transfer random data and RDD data to healthy executors. It usually takes between 30 seconds and 2 minutes before the final charge, depending on the cloud provider.
Databricks recommends enabling data transfer when enabling decommissioning. In general, the more data that is transferred, the less chance of errors, including failure to receive random data, loss of random data, and loss of RDD data. Data migration can also lead to reduced recalculations and cost savings.
Decommissioning is the best option and does not guarantee that all data can be transferred before the final eviction. Decommissioning cannot guarantee that tasks will not fail when trying to get random data from the executor.
When decommissioning is enabled, task failures caused by preemption of spot VM instances are not added to the total number of failed attempts. Task failures caused by preemption are not counted as failed attempts because the failure reason is external to the task and does not cause the job to fail.
Task failures caused by preemption are not counted as failed attempts because the failure reason is external to the task and does not cause the job to fail.
To enable decommissioning, you must set Spark configuration parameters and environment variables when creating the cluster:
-
To enable decommissioning for applications:
spark.decommission.enabled true
-
To enable shuffle data transfer during write-off:
spark.storage.decommission.enabled true spark.storage.decommission.shuffleBlocks.enabled true
-
To enable RDD cache data migration during decommissioning:
Note
If RDD StorageLevel replication is set to a value greater than 1, Databricks does not recommend enabling RDD data migration because replicas ensure that RDD data is not lost.
spark.storage.decommission.enabled true spark.storage.decommission.rddBlocks.enabled true
-
To enable retirement for worker roles:
SPARK_WORKER_OPTS="-Dspark.