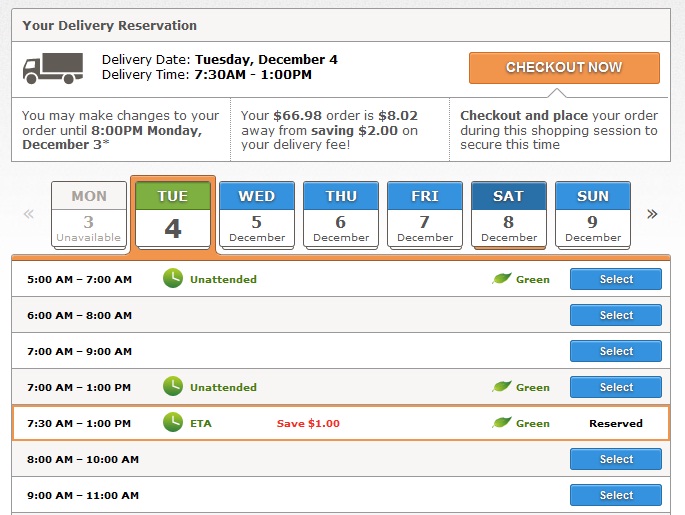
Predicting delivery date
A better way to predict baby's due date?
Story highlights
Only 5% of pregnant women deliver on their estimated due date
Predicting labor is a tough thing for doctors to do
CNN —
Of all the pregnant women you’ve known in your life, how many delivered their precious bundle of joy on their due date?
Probably not many. Only 5% of pregnant women deliver on their estimated due date, with most celebrating baby’s arrival one to three weeks early or late. But a new meta-analysis from Thomas Jefferson University in Philadelphia says a routine test might help moms late in pregnancy narrow the window when baby is expected.
“Measuring cervical length via ultrasound at around 37-39 weeks can give us a better sense of whether a mother will deliver soon or not,” Dr. Vincenzo Berghella, a senior author of the analysis, said in a press release.
The study analyzed the use of transvaginal ultrasound measurements of cervical length for 735 women with single-child term pregnancies and found when the cervix was 10 millimeters or less, there was an 85% chance the baby would be born within the next seven days. When the cervix was less than 30 millimeters, there was a 50% chance.
“Women always ask for a better sense of their delivery date in order to help them prepare for work leave, or to make contingency plans for sibling-care during labor,” said Berghella, who is director of maternal fetal medicine at Thomas Jefferson University Hospital. “These are plans which help reduce a woman’s anxiety about the onset of labor,” allow “providers and birth locals” to better plan staff and coverage, and help women decide if they should go with repeat caesarean delivery or attempt vaginal birth.
“These are plans which help reduce a woman’s anxiety about the onset of labor,” allow “providers and birth locals” to better plan staff and coverage, and help women decide if they should go with repeat caesarean delivery or attempt vaginal birth.
Doctors contacted by CNN weren’t so sure about the study’s conclusions.
“This seems more like a party trick, rather than a useful tool,” said Dr. Katie Babaliaros, an OB-GYN with Peachtree Women’s Specialists in Atlanta. “At the very best, there’s still 15% of these women who are going to be saying ‘Where’s my baby?’”
“Checking a cervical length at term only gives a window of time, in weeks, in which a woman may deliver,” said Dr. Dian Tossy Fogle, a perinatologist at Northside Hospital Center for Perinatal Medicine in Atlanta. “Most patients are already prepared that delivery will be occurring in the near future and have taken precautions. I do not see a real use for this in daily clinical care.”
Dian Tossy Fogle, a perinatologist at Northside Hospital Center for Perinatal Medicine in Atlanta. “Most patients are already prepared that delivery will be occurring in the near future and have taken precautions. I do not see a real use for this in daily clinical care.”
To determine a due date, doctors use a simple calculation using the first day of a woman’s last menstrual period. They then add 280 days to get to what would be considered a “term” baby: 40 weeks of gestation.
“This can be confirmed, ideally, by a first trimester ultrasound,” Fogle said. “If the menstrual period is unknown, then an ultrasound may be performed to establish a due date. First trimester ultrasounds are very accurate in determining the due date.”
First trimester ultrasounds are very accurate in determining the due date.”
The problem with knowing if baby will actually be born on that due date is that science isn’t sure about all the reasons why a woman goes into labor.
“There are many factors that are unknown and beyond the control of women or the best medical experts that will predict when a baby will deliver,” said Dr. Pratima Gupta from Physicians for Reproductive Health.
“We just don’t know how all the pieces all fit together,” Babaliaros said. “In the weeks leading up to delivery, there are a ton of hormones and chemicals that are released by the mom and the baby to trigger labor and those occur in very complicated ways.”
“In the weeks leading up to delivery, there are a ton of hormones and chemicals that are released by the mom and the baby to trigger labor and those occur in very complicated ways.”
To further burst the bubble of women hoping for a more accurate delivery date, the experts CNN talked to mentioned several downsides to transvaginal ultrasounds.
“My concern with this study is that it will increase health care costs with no clinical benefit,” Fogle said. “If the goal is to reduce ‘maternal anxiety’ regarding timing of delivery, a simple physical exam of the cervix performed at a routine OB visit can also give a patient an idea of how soon they will deliver. ”
”
The transvaginal ultrasound also won’t necessarily produce a more accurate measurement, experts said.
“Cervical length measurement can vary depending on the provider performing it,” Gupta said of the ultrasounds. “Therefore, the potential downside to this new technique is that a woman is given an (estimated due date) that is inaccurate due to the subjectivity of who did the measurement.”
Fetal medicine specialist Dr. Ashley Roman, director of the division of maternal fetal medicine at NYU Langone Medical Center, said it might be helpful for some patients with rare planning needs.
“The patient who has a partner who is traveling out of town or who is serving abroad in the military,” Roman said. “If the cervical length is less than 10 millimeters, it might be time to hang around.”
“But even if the cervical length is greater than 30 millimeters, the chance of delivering in the next week is like flipping a coin. ‘Who knows?’ This data isn’t that helpful because this is what we already tell our patients.”
Your Due Date is Wrong. The Imperfect Science of Due Date Prediction.
Both of my daughters arrived “late” according to the dates in my charts. Both girls seemed to mock the very concept of a “Due Date”. The little one, especially—she showed up a mere 30 minutes before my scheduled induction, 11 days after the day she was clinically expected to arrive.
The little one, especially—she showed up a mere 30 minutes before my scheduled induction, 11 days after the day she was clinically expected to arrive.
I am not alone. The chance of delivering exactly on your magically assigned date is rare — only 5% of women will deliver on their Estimated Due Date.
So there’s a pretty good chance that your due date is wrong too.
But why are we so bad at accurately predicting due dates?
Assigning a due date takes several factors into account: last menstrual period as a proxy for the assumed day of ovulation, size of the baby at various stages (assessed via ultrasound).
A study compared these traditional methods in the cases of nearly 20,000 births. The researchers found that precise prediction is basically impossible. Regardless of which method they used to determine estimated Date of Birth, the actual Date of Birth showed considerable variation between babies (up to 2 weeks before, and 2 weeks after). Even with the earliest ultrasound, between 11–14 weeks when the fetus is lime-sized, the size of said lime appears to vary just enough to screw up any degree of predictability.
Even with the earliest ultrasound, between 11–14 weeks when the fetus is lime-sized, the size of said lime appears to vary just enough to screw up any degree of predictability.
“Expectant mothers should be informed that there is only a 35% chance that they will actually go into labor during the week of their Estimated Date of Birth” – Khambalia, et al. 2001
Forget those fancy tools of due date prediction, a 2015 research study proved out what we’ve always known – babies don’t play by our rules.
In this study, researchers found that gestation lengths for normal pregnancies can vary up to 5 weeks. FIVE WEEKS! The researchers in this study knew exactly which day the little egg popped out of the ovary and started its journey to becoming a human. No guessing on last period or assuming ovulation date. This method is precision timing at its best.
Gestation lengths for normal pregnancies can vary up to 5 weeks
Five weeks is obviously a huge window. This study suggests that human gestation may be a bit more complicated than previously expected. Even after the sperm race concludes and genetic material combines, the uterus-bound ball of cells does not follow a consistent trajectory. It can take the fast, direct route or the slow, scenic route before it nuzzles its way into the uterine lining and sets up shop. Even crazier, the environment that mom provides for the little ball of cells can also influence timing. All these little influences along the way then lead to a shifted developmental timeline that throws off our current methods of predicting due dates.
This study suggests that human gestation may be a bit more complicated than previously expected. Even after the sperm race concludes and genetic material combines, the uterus-bound ball of cells does not follow a consistent trajectory. It can take the fast, direct route or the slow, scenic route before it nuzzles its way into the uterine lining and sets up shop. Even crazier, the environment that mom provides for the little ball of cells can also influence timing. All these little influences along the way then lead to a shifted developmental timeline that throws off our current methods of predicting due dates.
Essentially, each tiny human can be fast out of the gate or slow. Fast embryos are born sooner.
“The trajectory for the timing of delivery may be set in early pregnancy” — Jukic, et al. 2013
Genetic factors for your
real Due DateComparisons of mom and dad’s birth record vs. their babies birth date also suggest that genetics play an important role in due date prediction. Simply put, faster-growing babies hit escape trigger earlier than slower growing babies.
Simply put, faster-growing babies hit escape trigger earlier than slower growing babies.
But is the trigger baby size? or size of the remaining space in the uterus?
Seems like it’s the latter: babies squished into tight spaces may pull the trigger earlier! Short moms (>5’3”) deliver their babies almost five days earlier than their tall mom counterparts (>5’6”). But it’s not all genetic effects on baby size – tall or short dads had zero influence on when baby arrived. And babies of tall moms tend to come post due date, suggesting that the extra space may stall baby escape plans. Biologically speaking, uterine stretch may have something to do with when and how the body starts the labor process.
Essentially, each tiny human can be fast out of the gate or slow.
Fast embryos are born sooner.
Do Due Dates even matter?
We, as mothers and fathers, and anyone who has ever hounded a pregnant woman with the “when are you due?” question expect and crave predictability. We want a due “date”. But beyond satisfying the curious neighbor or aunt, there are serious implications for placing too much emphasis on a specific date.
We want a due “date”. But beyond satisfying the curious neighbor or aunt, there are serious implications for placing too much emphasis on a specific date.
If we don’t really know what the actual gestation length should be for each specific baby, how do we know who is early, who is late, and who is right on time?
Due dates serve an important clinical purpose—they provide information on when to intervene, speed things along, and get that baby out.
This may happen too early, before baby is ready. That is bad.
Or, it may happen too late. That is really bad.
One study found that baby girls have later estimated due dates than they probably should. As a result, girls have a higher risk of going post-term with serious consequences. Emphasizing the need to balance consequences of unnecessary early intervention with the possibility of intervening too late, the researchers on that study suggest a simple solution. They advise keeping a close eye on pregnancies with a wider window consideration of “post-date” and allow mom to have a strong voice in the decision about when to intervene.
They suggest putting all the cards on the table:
“Let women make an informed decision about which management they prefer… fully inform mothers about the uncertainties of pregnancy dating.” — Skalkido, et al. 2010
It doesn’t clear up the uncertainty but including women in the decision making process with full transparency about the BS of due date calculation, seems like a step in the right direction.
YOUR PREGNANCY SMARTS. Delivered.
Sign up for the Preg U Newsletter!
how SberMarket predicts what you will order on Friday evening / Habr
Hello! My name is Andrey Zakharov, I am a Senior Data Scientist at SberMarket. When you order groceries for Friday dinner, we need to make sure there are enough pickers and couriers to deliver. Therefore, we predict the number of orders in each store up to an hour. In the article - how we did it on data that is already outdated in 3 months.
More and more people are ordering food: delivery is faster, planning is easier, apps are more convenient and understandable. For our part, we connect new stores and expand delivery areas. In 2021, we delivered 4 times more orders than in 2020.
Because of this difference in demand "then" and "now", the old order data is not a good fit for forecasting sales volumes. In other words, the historical demand trend creates data inhomogeneity in the training dataset, and it reduces the accuracy of the model after training.
But we want to use the maximum amount of historical data, including demand and a year and two ago. After all, people buy for the same reasons, it's just that the total volume of consumption changes.
To solve this problem, we have replaced the forecast of a specific number of orders with a forecast of their rate of growth, ie, a derivative. So we use the demand history for the entire observation period.
We forecast the number of orders 14 days ahead based on the previous 21 days.
Based on the history of all the stores we work with, we have collected about a million training pairs for the model. As input, we provide the volume of demand in each store, its opening hours, size, number of unique commodity items, geographic location, SberMarket marketing promotions, plans for opening new stores, and weather. The output is the demand for the next 14 days.
An example of a training pair for a specific store on June 1, 2022
The number of orders not only varies within a store, but also varies between stores of different sizes. There are hundreds of orders per day in hypermarkets, and dozens, if not a few, in small stores. If you use all the data for training, the accuracy decreases.
We solve both of these problems by normalizing the data - by moving from absolute demand to the rate of its change. Normalization occurs within each training pair of the dataset. It is performed as follows:
- The median demand me(7) over the last seven days is calculated.

- This median divides 21 input demand values and 14 output demand values.
Demand normalization for a particular store on June 1, 2022
Let me explain why we choose normalization by the median, and not by the average value (expectation). Sometimes the number of orders atypically grows several times for a couple of days. This can be either the result of an active advertising campaign by SberMarket or a combination of external circumstances.
The mean value is sensitive to such outliers. For a number of values {10; ten; ten; 1000 ; ten; ten; 10}, the mean is 151, and the median is 10. Therefore, in order to achieve uniformity in the dataset, we normalize the data using the median.
For each day of the forecast, we build a separate model that predicts demand in relation to the median of the previous week. We tested creating one shared model instead of 14 separate ones. Its parameters included the “lag” of the forecast in days (i from 1 to 14, “on which day the forecast is made”). But this option showed worse results.
But this option showed worse results.
We are using an LGBMRegressor which uses gradient boosting. In boosting hyperparameters, you can set init_score - the value around which the search for a solution begins. Since we have moved to relative values, which fluctuate around one from day to day, we set init_score = 1.
When the model is trained on historical data, we substitute the real demand values \u200b\u200bfor the last 21 days and multiply them by the median for the past week . The model returns a forecast of the number of orders for 14 days.
Forecast and fact for May in one of the stores
The total number of orders for the day is good. But during the day, demand also changes. There are fewer orders in the middle of the day, and much more in the morning and evening. We have the ability to adjust employee shifts to hourly workloads if we can predict them. So we are working on the forecast up to every hour of working time.
For this we use the distribution of the number of orders by hours for the last three weeks. We calculate an average profile for each day, taking into account what day of the week it is, whether it is a weekend, a holiday, or a workday.
Hourly distribution of orders. On weekdays, most orders are before and after work. Demand is more even on weekends
Having daily profiles, we distribute the number of orders predicted for each day by hours. We get the required hourly forecasts.
The value normalization approach was introduced gradually. As a quality metric, we use the average absolute percentage deviation of MAPE. The graph shows how we gradually introduced improvements to the algorithm, including the normalization approach.
Improvement over time in the forecast for one of the stores. The lower the MAPE value, the more accurate the forecast
Demand forecast in each city
- We plan to hire pickers and couriers for a month in each city, taking into account the expected delivery load.
- Forecast period: for every day within a month.
- At the input of the model, we additionally submit plans for opening new outlets in the city.
To solve this problem, the dataset is formed from the total values of demand by city. Note that there is a temptation to simply take the forecasts for every store in the city and sum them up.
This is a common novice mistake. You need to create a separate dataset and train the model to predict demand at the city level. Thanks to the law of large numbers, data for an entire city experiences much less statistical fluctuation than data for individual stores. Here the rule is simple: what you predict is what training should take place on.
Forecast of demand and turnover throughout the country
- We plan the budget of SberMarket and monitor the implementation of the plan throughout the country.
- Forecast period: for every day within a month.
- At the input of the model, we additionally submit an average check, since we reflect the turnover in the plan.

The training dataset is formed from the values of demand in Russia. Similar to the situation with cities, a separate model is created for the forecast throughout the country.
Demand forecast in the new store
- We plan the number of couriers and pickers in the new store.
- Forecast period: for every day during the month.
- The new store has no order history, so we build a forecast based on data from nearby similar stores. For a new Magnet that opens in a city, we make a prediction based on other Magnets in the same city. An approach to solving this problem is the subject of a separate article.
Our historical data normalization approach is universal. In the fall of 2021, I tested it in a petrochemicals demand forecasting competition. My model took 1st place. If you want to understand how it works, here is the data and the solution on github.
My model is in the first line.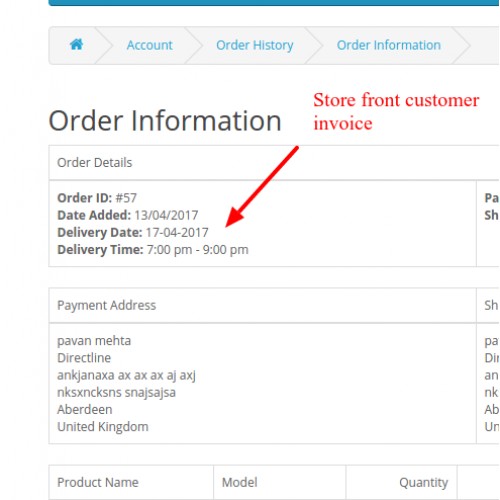 The lower the number in the “Result” column, the better the result (this is a deviation from the true values statistics)
The lower the number in the “Result” column, the better the result (this is a deviation from the true values statistics)
We started social networks with news and announcements from the Tech team. If you want to know what's under the hood of a highly loaded e-commerce, follow us where it's most convenient for you: Telegram, VK.
An introduction to food delivery forecasting
Publication date Nov 16, 2018
Get yourself ready to eat.Delivery time forecasting has long been a part of urban logistics, but processing accuracy has recently become very important for services such as Deliveroo, Foodpanda and Uber Eats, which deliver groceries on demand.
These and other similar services must receive the order and deliver it within ~30 minutes to put their users at ease. In these situations, +/- 5 minutes can make a big difference, so it is essential to customer satisfaction that the initial forecast is very accurate and that any delays are communicated effectively.
In this article, I'll talk about my experience building a (real) delivery time prediction model for a food delivery startup and how it gave better predictions than our trained operations team.
This article will cover the technical topics of machine learning and will focus on the business knowledge required to build a well-functioning predictive model. Links to external resources for further reading will also be included for your convenience.
Our roadmap:
- Statement Problem Problem
- Data Data
- ⚒️ Instrumentation
- 📈 Modeling
- 🤔 Improvement of grades
To start, let's formulate the problem with the formulation of the problem, with the formulation of the problem, with the formulation of the problem, with the formulation of the problem, with the formulation of the problem. This will help us focus on the goal.
We would like to build a model that takes food delivery data as input and then outputs a desired pickup time to inform drivers.

Some other things to note:
- The shipments are large and one might assume they require cars.
- Vendors (or vendors) range from restaurants to food service establishments and can have very different characteristics.
- It can be assumed that the drivers will arrive at the supplier exactly at the set time. In fact, this is not always the case, but with enough drivers, this can be minimized.
- Food should not be delivered too late as the customer will be waiting and angry and not too early as they will have to sit out before the customer is ready to eat it.
As input to our model, we have three categories of data that are typical of this kind of problem:
- Orders: what do people order? what supplier do they order from? what time is delivery?
- Customers: who orders? where they are?
- Delivery results: for previous deliveries, how did we perform? how long did each step take?
Delivery Data Example:
Delivery Team : Deliveries 'R' Us
Order_ID : 12345
Agent_Name : Bob Driver
Supplier : Delicious Donuts
Customer : Big Corporation Inc.
Pickup_Address : Shop 1, Busy Street, 23456, Hong Kong
Delivery_Address : Level 9, Skyscraper, 34567, Hong Kong
Delivery_Time : 05/29/2016 08:00:00 AM
Order_Size : $500
Since we have a lot of text, we need to process the data first to get it ready for the computer format.
Addresses can be processed using regular expressions to obtain more structured information. Key points: floor, building, zip code, area, country.
After the above processing, building, zip code, provinces, and zip codes can be combined with other variables to perform fast coding. One hot encoding will create many binary variables for every possible text. These numerical variables can then be fed into our models. You can read more introduction about hot coding here.0003
Training
We will use data from previous shipments to train the model, including estimated delivery times and actual delivery times (the target variable for our exercise). For this article, we will be working with 1000 data points.
Before we go deeper, we need to think about what models would be best for solving the problem we have. The diagram below from the Scikit-Learn documentation provides a great way to decide which algorithm to use.
Who said that machine learning is a tough discipline? Credit: Scikit-Learn Documentation,Let's see what we know about our problem:
- As mentioned earlier, we have over 1000 data points to train.
- Model output must be numeric values.
- Due to hot coding, we are left with quite a large number of binary variables, which means that many features are important.
With this in mind, we can follow the diagram above to achieve Ridge regression and SVR with a linear kernel. For simplicity, we'll just work with the Ridge Regression and also add a Random Forest Regressor to see how it works on the data in different ways.
If you are interested in more information, you can read about the algorithms on their respective pages in the Scikit-Learn documentation: Ridge Regression, SVR (Support Vector Regression) and Random Forest Regression,
Performance Measures
, which we will use to evaluate the performance of our model.
A common metric we can use to get a quick idea of our performance is the Mean Absolute Error (MAE). This tells us the average difference between our estimated delivery times and actual delivery times.
Going forward, we can define two more domain-specific metrics:
- Mostly on time (<5 minutes late)
- OK, we are small late (<10 minutes late)
These two metrics tell us how often we upset users. If we are 15 minutes late or 25 minutes late, it doesn't matter to the user, we are just very late , MAE doesn't realize this and will consider one worse than the other, but from a business point of view it is actually the same thing, and important so that our model understands this.
We'll actually be using the reverse metric (i.e. more than 5 minutes late delivery) as they are a bit easier to work with.
So, a quick summary: we know what we need to do, we know what data we need to do it with, and we know how we will do it - so let's do it!
Fortunately, data science doesn't require so many hands. Photo credit: Rand Faith,
Photo credit: Rand Faith, Let's think about food delivery. We can break it down into three main components:
- Pick up food from a vendor.
- Moving from supplier to buyer.
- Give food to a customer.
We can predict the time required for each component and then add them together to get the final delivery time.
Delivery Time = Pick-up Time + Point-to-Point Time + Drop-off Time
Alternatively, we could train the model to predict the entire delivery time. The reason we have to break this down is because specialty models, which will have superior ability compared to one general model. If we replace models with people, it makes sense. On your business development team, you will have someone who really knows the suppliers well and how long they can take to deliver. On your customer service team, you will have someone who knows each customer well and can predict how long a delivery might take based on their location and building. We structure our process with this in mind.
We structure our process with this in mind.
Now that we have three steps, let's dive into them and create our models.
Pickup Supplier
When the driver arrives at the destination, he must find a parking lot, pick up food and get to the car. Let's take a look at the potential complications that may arise during this process.
- No park: For restaurants located in the city center, this can be significantly more difficult compared to restaurants located in more residential areas. We may use postal code or latitude/longitude information to collect this information. I found that postcodes were especially valuable as they collect high level general information due to their specific structure.
- Difficult access: Restaurants will generally be fairly easy to reach as they rely on it to serve customers, but food service establishments can be in industrial areas and also not have an obvious entrance, making it difficult.
 As above, we may use location information when adding a vendor category.
As above, we may use location information when adding a vendor category. - Food not ready: Since order sizes can be quite large, it is not uncommon for food not to be ready. To deal with this, the supplier can be contacted on the day of collection to check that the food will be ready on time. A response to these messages would be a useful flag to understand our times. The presence or absence of a specific supplier can also be a useful input. Finally, order size is a good indicator; when cooking a small amount of food, not much can go wrong, but when it lasts up to 100 people, there is much more chance that something will go wrong.
- What is missing in the order: The driver must check the order upon arrival and in some cases they may find something missing. This means that they have to wait for the extra food to be prepared. Again, this probably depends on the supplier and how busy they are at the time of pickup.
For this part of the problem, we will use the following data:
Supplier : Delicious Donuts
Customer : Big Corporation Inc.
Pickup_Address : Shop 1, Busy Street, 23456, Hong Kong
Delivery_Time : 05/29/2016 08:00:00 AM
Order_Size : $500
After doing the processing as described above, the data can be passed to our Scikit-Learn models , resulting in:
Baseline Results:
Mean Absolute Error: 544 seconds
Greater than 5 mins late: 55%
Greater than 10 mins late: 19%Random Forest Results:
Mean Absolute Error: 575 seconds
Greater less than 5 mins late: 42%
Greater than 10 mins late: 22%Linear Regressor Results:
Mean Absolute Error: 550 seconds
Greater than 5 mins late: 44%
Greater than 10 mins late: 17% 549 seconds
Greater than 5 mins late: 45%
Greater than 10 mins late: 17%
It can be seen that if we use the base mean absolute error (MAE) metric, all models perform worse than the base model. However, if we look at the metrics that are more relevant to the food delivery business, we can see that each model has its own advantages.
The Random Forest model reduces orders more than 5 minutes late by almost 25%. The linear regressor does its best to reduce orders that are 10 minutes late by about 10%. Interestingly, the ensemble model performs fairly well on both metrics, but notably, it has the lowest MAE of the three models.
When choosing the right model, business goals come first, which dictate the choice of important metrics and, therefore, the right model. With this motivation, we will stick to the ensemble model
Point-to-point
Estimating travel time between destinations is difficult for many reasons; There are thousands of routes to choose from, traffic conditions that are constantly changing, road closures and accidents; All of this provides a lot of unpredictability for any model you might create.
Lucky for us, there is a group of people who have thought long and hard about this issue and are collecting millions of data points to help us better understand the environment. Google comes.
Google comes.
To predict travel time from point to point, we will call the Google Maps API with known pick-up and drop-off points. The returned results include traffic and worst-case parameters that we can use as input to the model. The API call is quite simple, it looks like this:
gmaps = googlemaps.Client(key='MY_API_KEY')params = {'mode': 'driving',
'alternatives': False,
'avoid': 'tolls',
'language': 'en',
'units': 'metric',
'region': country}directions_result = gmaps.directions(pick_up_location,
drop_off_location,
arrival_time=arrival_time,
**params) we can get a very accurate result for a problem that has already been well thought out. It is important not to redo the work, Always think, if there is already a good enough solution to your problem, don't reinvent the wheel!
Prior to implementing this model, our organization used the Google Maps public interface to predict delivery times. Thus, the performance of our new model for this part of the path is identical to the baseline. Thus, we will not calculate any comparisons here.
Thus, the performance of our new model for this part of the path is identical to the baseline. Thus, we will not calculate any comparisons here.
An important note is that addresses are not always well-formed! When querying Google Maps, there is always a chance that they will respond by saying: Uh… I don't know ”, to which we should have an answer. This is a great example of how humans and machines should work together. If the address is not formed properly, the operator can come in and clarify the address or even call the client to clarify the information.
With this, we can move on to the third part of our model.
Customer drop off
As soon as the driver arrives, he must find the park, deliver the food to the right person and get a final answer. Potential issues along the way include:
- The car park has height restrictions: It's simple, but many deliveries happen in vans, in which case there may be height restrictions preventing drivers from using the main entrance.

- The building has no parking: This is obvious. The lack of parking means that the driver must devote time to driving and finding a place to leave their vehicle at the time of delivery.
- Building security question: Most modern office buildings require a security card for access. In the best case, drivers can simply be scrolled through, but in the worst case, drivers may be required to move to another location, register for a card, and then use the back door.
- Client on a high floor or in a difficult location It may seem ridiculous, but in some office buildings it is very difficult to move around with different elevators for different floors, and for small companies they can be hidden in the labyrinth of hallways.
All things considered, the zip code is a great indicator, as it tells us if we can expect a business area or a residential area. We can also dive deeper into the address. For example, if we have level 40, it is quite obvious that the delivery will be in a large tower block and will probably have a complex security process.
For this part of the problem, we will use the following data.
Customer : Big Corporation Inc.
Delivery_Address : Level 9, Skyscraper, 34567, Hong Kong
Delivery_Time : 29/05/2016 08:00:00
Order_Size : $500
After typical processing and running our models, we see the following:
Baseline Results:
Mean Absolute Error: 351 seconds
Greater than 5 mins late: 35%
Greater than 10 mins late: 0%Random Forest Results:
Mean Absolute Error: 296 seconds
Greater than 5 mins late: 15%
Greater than 10 mins late: 7%Linear Regressor Results:
Mean Absolute Error: 300 seconds
Greater than 5 mins late: 14%
Greater than 10 mins late: 5% mins late: 6%
Here we can see a 17% decrease in MAE, which is much better than before. Similarly, we are seeing a whopping 63% reduction in bookings over 5 minutes late. On the other hand, the model increases the number of late orders from 0% to 6%. Again, we are faced with a trade-off between models that have their merits, and we must let our KPIs of business.
Again, we are faced with a trade-off between models that have their merits, and we must let our KPIs of business.
Now we can combine our models with the following formula:
Delivery Time = Pick-up Time + Point-to-Point Time + Drop-off Time
+ Hyperparamater
Note the addition of a hyperparameter this time. We'll add this to account for any other weird effects we see in the data, such as the pickup time was always set 5 minutes early to match driver expectations. We will set this option to minimize the final error rates after calculating the combined results.
Putting it all together, we get the final result:
Baseline Results:
Mean Absolute Error: 1429 seconds
Greater than 5 mins late: 60%
Greater than 10 mins late: 19%Ensemble Results:
Mean Absolute Error: 1263 seconds
Greater than 5 mins late: 41%
Greater than 10 mins late: 12%
So our final model greatly improved the base model in every way - we did it!
That feeling when your food finally arrives! Photo credit: Sander Dahlhuizen Most importantly, we've seen a drop in bookings over 10 minutes late by nearly 40%! We were able to achieve this by working on three separate models that were optimized for their specific business needs. Combining them and refining them at the last step, we made sure that we created a model that is at the level of trained specialists
Combining them and refining them at the last step, we made sure that we created a model that is at the level of trained specialists
Having a model that gives even more accuracy would be great, but it would also require a lot more effort due law of diminishing returns. Instead, there are other solutions if we think more about the business case than machine learning.
Late versus early age
As you remember from the beginning, this model is designed for catering, which means we know the delivery time in advance. One easy way to avoid late deliveries is to take any value of the model's results and scale it up to make sure we're early enough.
This is not a good solution because too early also has the problem that the food may go bad or be unprepared. However, this raises the question that we should consider the distribution of ‘ late ' and ' precocity '. Maybe it's better if we arrive 10 minutes early than 5 minutes early. With the metrics used up to this point, we have not optimized for such scenarios and so we may revisit this and optimize accordingly.
Delivery windows
Another thing to consider is how the model is presented to users. If the user is told that you will arrive at 2 pm and you are not, they will be disappointed. If you tell someone you'll be there between 1:45 pm and 2:00 pm, then you can aim for a 1:50 pm delivery, and if you're a little late, you'll have a reprieve.
It is always important to consider machine learning problems as a solution to a real real world problem - this context can often lead to "improvements" that would otherwise not be possible in the model itself.
Supplier Feedback
One of the key wins of this model was the ability to effectively differentiate supplier lead times. This tells us that vendors must have very different metrics.
Digging deeper, drivers were spending 3 times as much time with multiple suppliers. With this information coming back to the business world, you can discuss with suppliers and identify issues that can reduce the time spent on these suppliers and, by reducing variances, improve the overall performance of the model.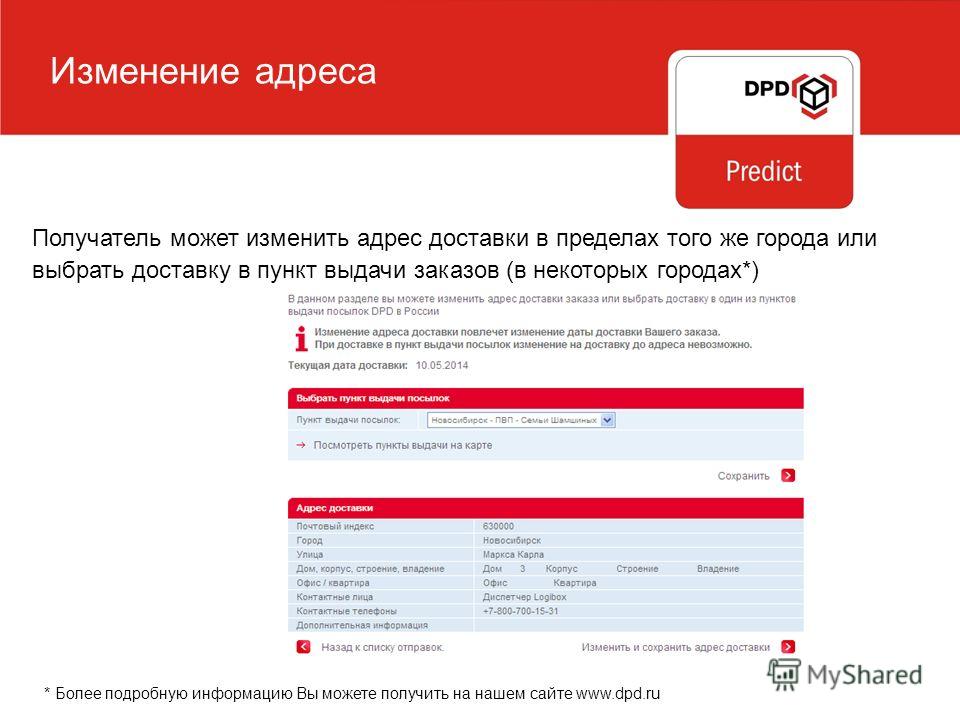
We started by setting up a problem for predicting the timing of food delivery. We have decided what data we will use and what processing we should do. We thought about which models would be the best for solving our particular problem. We then split our problem into three components to build target models and finally put them together to create a fully functioning predictive model. We didn't stop there, but used our business knowledge to improve the efficiency of our model.
This resulted in a 40% reduction in bookings more than 10 minutes late, which can be converted directly into dollars saved in refunds. It also helped reduce the burden on the operations team, allowing them to focus on higher-value tasks such as improving supplier performance.
As mentioned, this is a general procedure that can be used to apply machine learning to business problems. This is an approach that ensures that the fundamentals are understood correctly before further optimization for an additional few percent improvement.